논문 링크 :https://arxiv.org/abs/1807.03888
A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks
Detecting test samples drawn sufficiently far away from the training distribution statistically or adversarially is a fundamental requirement for deploying a good classifier in many real-world machine learning applications. However, deep neural networks wi
arxiv.org
해당 논문은 ODIN 이후에 나온 논문으로, OOD detection 분야 milestone 논문 중 하나이다.
- Introduction

Out-of-Distribution Detection을 위해서 softmax vector를 이용한 기존의 논문들과 달리 해당 논문은 feature extractor의 출력으로 나온 feature 공간에서의 feature vector를 이용하여 OOD를 detection 한다. 이때 Mahalnobis distance라는 metric을 사용한다는 것이 논문의 특징이다.
방법에 대한 설명전, 논문의 contribution은 다음과 같다.
1. 본 논문에서는 OOD detection을 위한 재학습 없이 pre-trained 모델에 적용할 수 있는 간단하고 효과적인 OOD detection method를 제안한다.
2. 논문에서는 특정 class 분포와의 Mahalnobis 거리를 기반으로한 score를 제안한다.
3. 제안된 방법의 검증을 위해 DenseNet, ResNet 모델에 대해서 CIFAR, SVHN, IMageNet, LSUN 등 다양한 벤치마크 데이터셋에서 실험을 진행한다.
논문에서 사용된 class별 분포의 평균과 전체 분산의 covariance는 위의 Notation과 같이 정의된다.
Mahalnobis distance-based score는 위의 M(x)와 같이 정의된다. 간단히 설명하면, 왼쪽 그림과 같이 각 색깔별 클레스의 평균점과 가장 가까운 평균점과의 거리라고 이해할 수 있다. 이 때 사용하는 거리 metric을 Mahalnobis distance metric을 사용하고, 해당 metric은 M(x)에 있는 식과 같이 일반적인 L2 distance 계산에 가운데 covariance의 역수를 곱해준다. 따라서 분산이 커질수록 거리의 값이 작아지는 것을 알 수 있다. 이는 오른쪽 그림과 같이 거리가 빨간색의 거리 길이가 같아도, 분산을 고려하여 거리를 계산하면 (b)가 더 큰 값을 가진다. 즉, Mahalnobis distance는 일반적인 L1,2 distance와 달리 분산을 고려하여 거리를 계산하고, 해당 논문에서는 이를 score로 사용하였다.
OOD data가 입력으로 들어오면, 기존의 ID class와의 거리가 먼 경향성이 있으므로, 왼쪽 그림처럼 보라색의 OOD 데이터가 들어오면, ID data들 보다 더 거리가 큰 distance 값을 가질 것이다. 이를 이용하여 OOD detection을 수행한다.
기존의 mahalnobis distance 방법은 classification 분류를 진행할때, feature 공간에서 특정 class 평균점과 가까운 class로 분류를 수행한다. 이렇게 분류를 수행할때, 위의 2번째 막대 그래프와 같이 accuracy 성능의 차이가 거의 없음을 알 수 있다. 또한 위의 3번째 그래프의 ROC curve에서 보는 것처럼 제안한 방법이 기존의 softmax기반 방법과, Euclidiean distance를 사용한 방법보다 성능이 더 좋다는 것을 보여주고 있다.
또한 논문에서는 feature extractor의 마지막 feature공간이 아닌 모든 layer에 대해서 성능을 측정하였는데, 위 슬라이드의 아래 그림처럼 반드시 마지막 layer가 성능이 좋지 않기 때문에, 논문에서는 모든 layer에서의 score에 가중치를 두어서 ensemble하는 추가적인 테크닉을 사용하였다.

또한 ODIN 에서 사용한 Input pre-processing 기법을 그대로 사용하였으며, 해당 방법을 사용하여 score의 차이를 늘려주도록 수행하였다. 아래는 ODIN 논문 리뷰글을 참고 할 수 있다.
https://gbjeong96.tistory.com/58
[논문리뷰] Enhancing The Reliability of Out-Of-Distribution Image Detection In Neural Networks
논문 링크 : https://arxiv.org/abs/1706.02690 Enhancing The Reliability of Out-of-distribution Image Detection in Neural Networks We consider the problem of detecting out-of-distribution images in neural networks. We propose ODIN, a simple and effective
gbjeong96.tistory.com
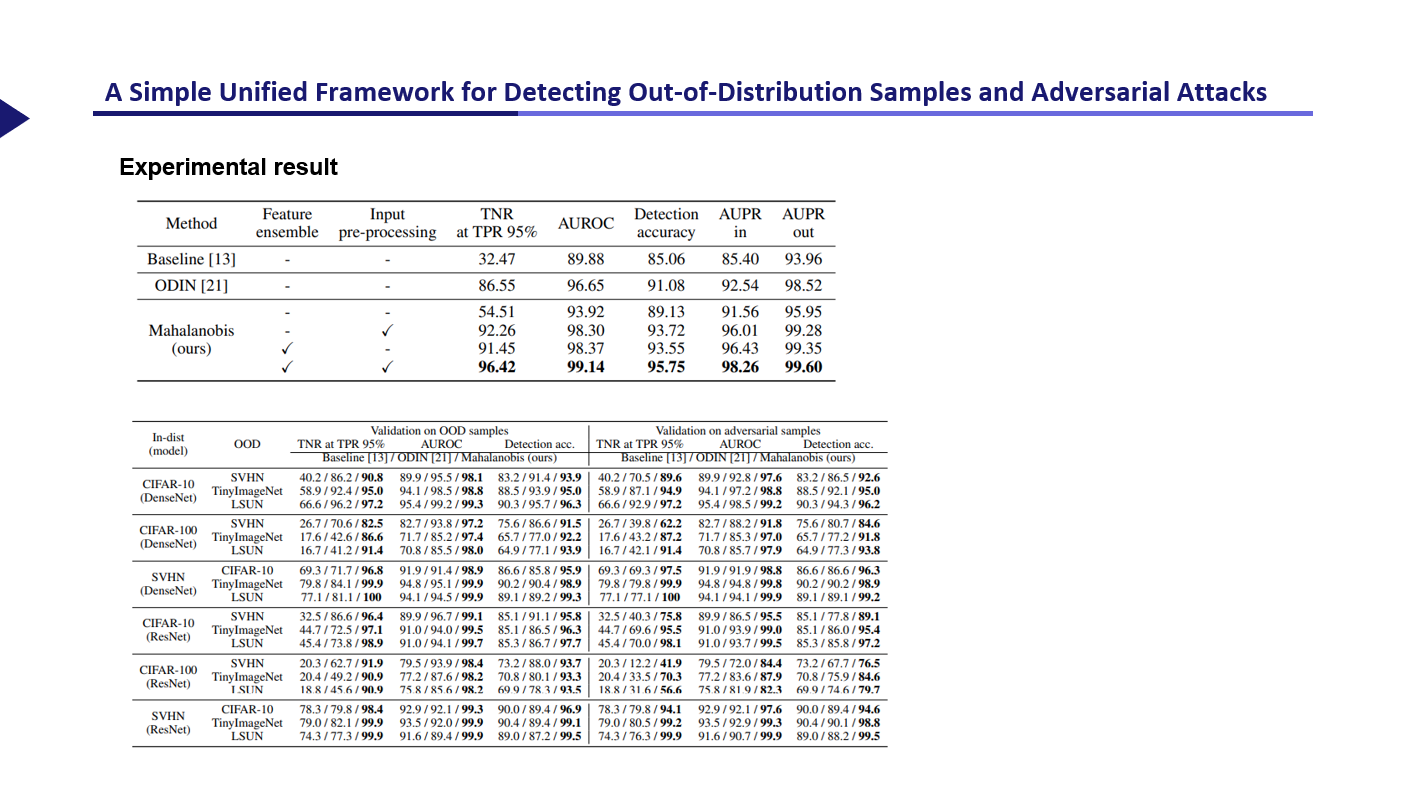
실험 결과, 위의 table을 통해 앞에서 소개한 ensemble과 input pre-processing을 적용하였을 때, 기존의 방법보다 더 좋은 성능을 보이는 것을 확인할 수 있었고, 아래의 테이블을 통해 다양한 dataset에서 기존의 baseline과 ODIN기법 보다 더 좋은 성능을 보임을 확인했다.
이상 논문리뷰였습니다.



