-강의 영상
-Activation Fuctnion


강의에서 첫번째로 설명하는 Sigmoid는 가장 기본적인 activation function이다. 해당 비선형 함수는 간단하지만 몇가지 문제점을 가지고 있는데, 첫번째는 x값이 오른쪽과 왼쪽으로 조금만 가도 gradient값이 0이 되어서 gradient가 흐르지 않는 Saturated 문제가 발생한다. 두번째는 non-zero centered 문제인데, 해당 문제는 2번째 그림과 같이 gradient가 한쪽 방향만 가질 수 있어서 update가 느리게 된다. 해당 문제가 발생하는 원인은 local gradient X에 upstream gradient를 곱할경우, non-zero centered 이면, 이전 layer에서 넘어온 x값은 항상 양수 만을 가지므로, X에 대한 Loss의 gradient는 upstream gradient와 동일하게 된다. (모든 wi에 대한 gradient는 동일한 upstream이 곱해지므로 부호가 모두 같게 된다.) 세번째 문제로 exponential computation 연산이 expensive 하다는 문제점이 있다. (exponential 연산은 큰 문제가 아님. 내적연산이 더 비용이 비쌈)

tanh는 sigmoid의 zero centered 문제를 해결했지만, 여전히 saturated 문제점이 존재한다.

ReLU는 CNN에서 흔히 사용하는 activation function으로 saturated 문제점을 해결했다. 하지만 여전히 zero centered 하지 않다는 문제가 있고, x<0 구간에서는 여전히 staturated 문제가 발생한다는 단점이 있다.
Dead ReLU는 이러한 Saturated 문제점 중 하나이다. 이러한 Dead ReLU 현상은 training data가 모여있는 지점(Data Cloud)에서 먼 지점으로 초평면(W*X)가 초기화 된 경우, Learning rate가 지나치게 높은 경우이다.

ReLU의 문제점을 보완해주기 위해서 다양한 버전들이 나왔다. Leaky ReLU는 negative 영역에도 기울기를 주어서 saturated 문제를 해결한다. 그리고 아예 negative 영역의 기울기를 학습가능한 알파라는 파라미터를 두어서 사용하는 PReLU도 소개한다. 그 밖에 ELU와 두 개의 선형함수를 취하는 Maxout function을 강의에서는 소개한다.
-Data Preprocessing

신경망의 성능을 높이기 위해서는 Data Preprocessing 과정이 중요하다. 해당 과정의 대표적인 기법으로 zero-centered data, normalized data를 사용한다. zero-centered는 특정 입력이 postive에 치우쳐져있거나, negative에 치우쳐저 있는 것을 방지하고, normalize는 모든 차원이 동일한 범위안에서 동등한 기여를 하도록 하는 작업이다. practical하게는 이미지의 경우는 전처리로 zero-cetering을 사용하고 normalization은 사용하지 않는다.(이미지는 각 차원간의 스케일이 어느정도 맞춰져있음.)
*Training에서 사용한 전처리의 평균을 Test 단계에서도 동일하게 사용한다. (배치 단위가 아닌 training 데이터 전체의 평균)

우리는 학습을 하기 위해서 가중치 W를 초기화 해야한다. 만약 가중치 W를 0에 가까운 아주 작은 값으로 초기화 되면 어떻게 될까? 위는 각 layer의 가중치를 0에 가까운 값으로 초기화 한것이다. 맨 아래의 그래프를 보면 알 수 있듯이 첫번째 layer에서는 가우시안을 따르는 그래프를 볼 수 있지만, 다음 layer에서 부터는 0에 가까운 값만 출력 되는 것을 볼 수 있다. 이는 forward pass하는 과정에서 작은 값의 W에 입력이 곱해져서 다음 값이 아주 작아져서 생기는 문제이다. Back propagation 역시 동일하게, X값이 곱해지므로 해당 X값이 아주 작아지면 gradient값도 아주 작아져서 update가 잘 일어나지 않는 문제점이 있다.
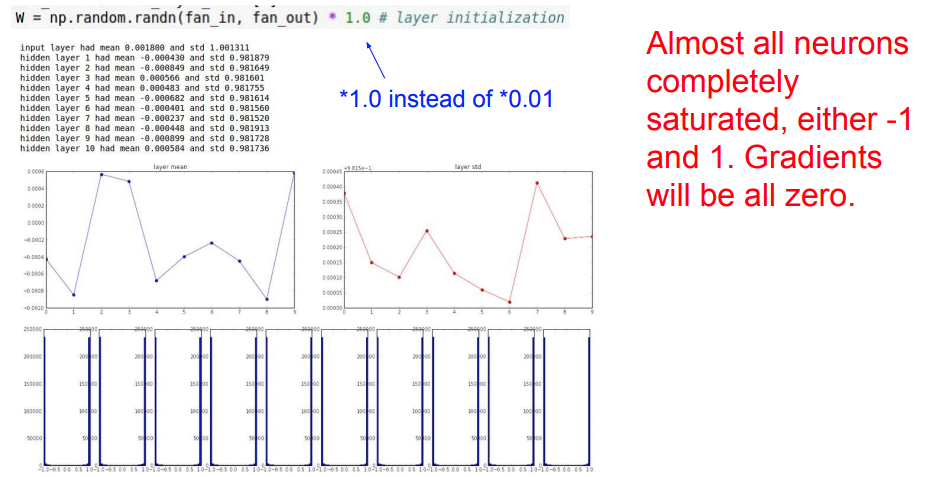
그렇다면 가중치 값의 초깃값이 크게 되면 어떻게 될까? 그러면 위와 같은 tanh의 경우에서는 W의 큰값이 곱해져서 Saturated 문제가 발생할 것이라고 예상할 수 있다. WX값이 커져서 forward 과정에서 1,-1에 가까운 값이 출력될것이다. 또한 Backward 과정에서는 gradient값이 0에 가까워져서 update가 일어나지 않을 것이라고 예상할 수 있다.
따라서 초기화의 문제점을 해결하기 위해서 강의에서는 Xavier initialization를 소개하고, ReLU에서는 Xavier initialization을 적용하기 위해서 나누기 2를 해주는 추가적인 기법을 적용한 사례를 소개한다.
-Batch Normalization
weight initialization에서 잘못된 initialization이 activation function을 통과하게 될경우를 살펴보았다. 우리는 네트워크가 잘 작동하기 위해서 이러한 activation function을 unit gaussian으로 만들고 싶고, Batch normalization은 이것을 명시적으로 해주는 기법이다. (강제적으로 unit gaussian을 만들자는 idea)

가중치를 잘 초기화 하는 것 대신에 layer마다 normalization 연산을 통해 모든 layer가 unit gaussian 형태가 되도록 만든다. 이를 위해서 위의 그림처럼 입력으로 들어오는 D차원을 가지는 N개의 x를 N개에 대한 평균과 분산을 이용하여 normalization 연산을 수행한다.
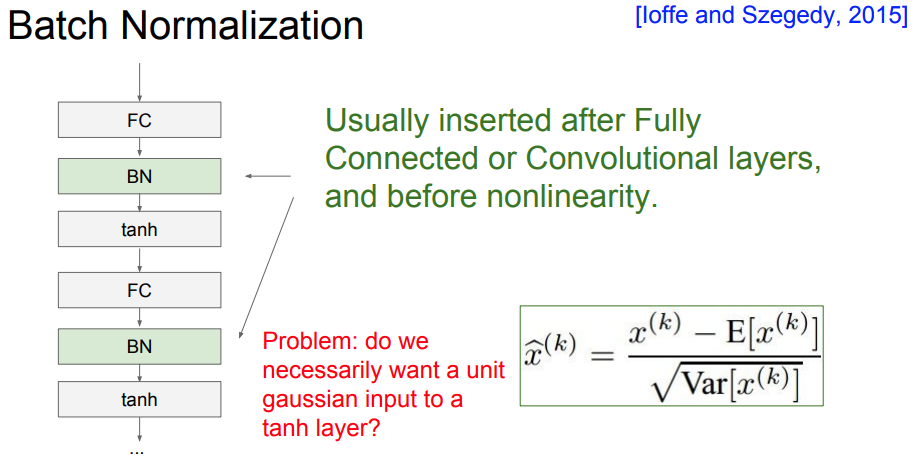
해당 normalization 연산은 activation fucntion 전에 수행하며, Convolution에서는 차원 별이 아닌 activation map(채널, depth)마다 평균과 분산을 하나씩 구해서 연산을 수행한다. 이러한 연산을 통해 각 layer마다 w가 지속적으로 곱해져서 생기는 bad scaling effect를 상쇄시킨다.

unit gaussian은 tanh에서 saturation을 완전 일어나지 않게 만드는데, staturation이 적절하게 일어나도록 조절하기 위해서 우리는 이러한 gaussian의 위치와 scale을 조절할 수 있는 감마와 베타 파라미터 값을 추가한다. 위의 그림에서의 감마는 스케일링 효과를, 베타는 이동의 효과를 준다. 따라서 이러한 감마와 베타 또한 학습 가능한 파라미터 값으로 설정하여 다시 원래의 분포로 돌아갈 수 있는 여지를 준다.(e.g. 감마 = 분산, 베타 = 평균)
결국 BN은 gradient의 흐름을 보다 원할하게 하여 학습이 더 잘되게 도와준다. 또한 해당 데이터 뿐 만 아니라 해당 batch의 다른 데이터의 분포를 고려하기 때문에 regularization 효과를 준다. 추가적으로 Test time시에는 추가적인 계산 없이 train time에서 사용한 평균과 분산 값을 사용한다.
(기계학습에서 데이터의 zero center, normalization에 대한 효과를 시각화해서 보여주는 자료 참고)
-Hyperparameter Optimization
우리는 학습이 잘 되게 하기 위해서 적절한 하이퍼 파라미터를 선택해야한다. 가장 좋은 하이퍼파라미터를 선택할 수 있는 방법 중 하나는 cross-validation 이다. cross-validation은 training set으로 학습시키고 validation set으로 평가하는 방법이다. 넓은 범위의 값을 선택하여 학습을 짧게하여 검증해보는 coarse stage를 수행하고나서 좀 더 좁은 범위를 설정하여 학습을 좀 더 길게 시켜보는 fine stage를 통해 최적의 값을 찾는다.

하이퍼파라미터를 찾는 방법은 Random Search와 Grid Search가 있는데, gird search는 고정된 값과 간격으로 샘플링하는 방식이다. 그림에서 알 수 있듯이 Random search를 이용하여 범위를 좁혀나가는 것이 더 효율적이다.
추가적으로 loss curve가 처음에는 평평하다가 갑자기 가파르게 내려가는 것은 초기화 문제, training과 valication accuracy가 큰 차이를 보이는 것은 overfit 문제로 regularization의 강도를 높여야 한다고 조언한다.
출처 : Stanford University School of Engineering, http://cs231n.stanford.edu/
'AI > cs231n' 카테고리의 다른 글
| [강의정리] Lecture 7: Training Neural Networks, Part 2 (0) | 2022.03.28 |
|---|---|
| [강의정리] Lecture 5: Convolutional Neural Networks (0) | 2021.09.24 |
| [강의정리] Lecture 3: Loss Functions and Optimization (0) | 2021.09.16 |
| [강의정리] Lecture 4: Backpropagation and Neural Networks (2) | 2021.09.13 |
| [강의정리] Lecture 2: Image Classification pipeline (0) | 2021.08.29 |



