해당 논문은 ECCV 2016에 실린 초창기 Continual learning에 관한 paper이다.
해당 논문은 새로운 task에 대해서 Continual한 상황에서 학습하는 방법을 제안한다. 이때 여러가지 방법을 사용할 수 있는데 기존의 method인 Fine-tuning, Feature Extraction, Joint Training과 논문에서 제안한 Learning without forgetting의 성능과 장단점을 비교한다.
-Feature extraction
공유된 파라미터와 old task 파라미터는 건드리지 않고, 1개 또는 하나 이상의 output layer가 새로운 task에 대한 feature로써 사용되어진다. 이때, 새로운 task에 대해서 성능을 발휘하지 못하는데, 그 이유는 공유 되어진 파라미터가 학습되어지기 않기 때문에 새로운 task를 구별하는 어떤 정보를 나타내지 못하기 때문이다.
-Fine-tuning
old task에 대한 parameter를 고정시키는 동안 shared parameter와 새로운 task에 대한 parameter를 new task에 대해서 optimize한다. 이때, 원래의 작업에 대한 new guidance 없이 shared parameter를 변화시키기 때문에 이전의 task에 대한 성능을 저하시킨다. 학습을 할 때에 shared parameter의 large drift를 방지하기 위해서 낮은 learning rate를 사용한다는 특징이 있다.
Duplicating and fine-tuning은 새로운 task가 추가될 때마다 선형적으로 test time이 증가하였다
-Joint Training
joint training은 shared parameter, old parameter, new parameter 모두를 공동으로 optimize한다. task가 많아질수록 점점 더 model이 cumbersome된다. joint training은 이전의 old task에 대한 data가 있다고 가정한 상태에서 학습을 수행하기 때문에 이전 task에 대한 학습데이터가 없다면 이용할 수 없다.
Joint training은 각 task에 대한 data set을 동일하게 sampling하고 모든 task에 대한 output layer의 loss의 합을 이용하여 학습을 수행한다.

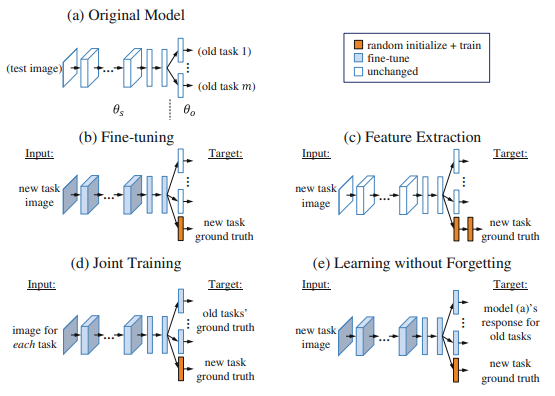
-Learning without Forgetting(LWF)

LWF의 method는 distillation을 이용하며, 비교적 간단하다. 먼저 새로운 data들에 대해서 old task의 output을 기존의 old task layer를 통과시켜서 출쳑된 Yo 값(logit)을 가지고 있고, new task layer의 parameter를 초기화 시킨다. 그리고 기존의 old task에 대한 label은 distillation한 logit 값 Y0를 사용하고 new task에 대한 label은 원핫 벡터를 사용한다. 따라서 위의 y헷 n은 sofrtmax output, y n은 one=hot vector이다.
각 new class에 대한 Node가 output layer 아래에 FC로 추가된다. parameter 수는 마지막 shared layer의 노드 수 곱하기 새로운 class의 수가 된다. 위에 표시된 R은 regularization term으로 paper에서는 weight decay로 0.0005를 사용하였다. 추가적인 Loss에 대한 자세한 식은 아래와 같다.



-Main Experiments
실험은 과거의 데이터를 가지고있는 상태에서 학습을 수행하는 joint-training을 upper bound로 설정하고 fine-tuning과 feature extraction을 LWF가 overperform하다는 것을 보여준다.

위의 Table을 통해서 single New Task Scenario에 대한 실험 성능을 평가한다. fine-tuning과 feature extraction, joint training의 성능은 LwF와의 상대적인 성능 수치를 나타낸다. 일반적으로 LwF의 성능이 joint training의 성능과 비슷했으며, fine-tuning과 feature extraction에서는 더 좋은 성능을 보여주었다.
실험결과 몇가지 특이점은 Places2 → CUB, ImageNet→MNIST와 같이 dissimilar한 dataset의 경우에는 old의 성능이 잘 나오지 못한다는 특징이 있었다. 그러한 이유는 dissimilar한 dataset의 task를 수행하면서 shared parameter의 drift를 야기하고 그 결과 LwF로 얻어진 ol
d task에 대한 logit값이 과거의 정보에 대해서 충분히 설명할 수 없기 되기 때문이다.

위의 그래프의 실험은 Multiple New task Scenario이다. 해당 상황은 task가 1번 바뀌는 경우가 아닌 여러번 바뀌는 경우를 보여준다. 그래프의 가로축을 보면 실험에서는 첫번째에서 두번째로 바뀔때에는 dataset이 바뀌고 2번째부터 4번째까지는 동일한 데이터셋에서 task가 바뀌는 경우를 가정한다. 이 경우 LwF는 매 time마다 Yo(distillation)를 다시 계산한다.
결과를 살펴보면, LwF는 fine-tuning보다 시간에 따른 성능감소가 느리며, 최종 time에서의 성능은 joint training과 유사하다는 것을 알 수 있다.

또한 data size가 method들의 성능과 관련이 있는지에 대한 평가를 위한 실험을 수행했다. 실험 결과 새로 들어오는 VOC의 data의 양이 감소할수록 old task에 대해서는 LwF와 fine-tuning의 차이가, new task에 대해서는 LwF와 feature extraction의 차이가 증가하는 것을 확인할 수 있었다. 또한 old task에 대해서는 joint training의 성능 저하율보다 LwF의 성능 저하률이 더 높은 것을 관찰할 수 있었다.
-Design Choices and Alternatives


-Choice of Task-Specific Layers
위의 그림 (a)와 같이 More task-specific layer는 각 task에 대한 output layer에 hidden layer를 추가하는 것이다. later layer는 좀 더 specific한 경향이 있기 때문에 layer를 추가하는 것이 효과적일것이라고 예상하나, 해당 방법은 더 많은 parameter를 요구하며 LwF의 경우 해당 layer를 추가하는 것이 성능향상에 별 도움이 되지 않았다. 위의 Table (a)는 해당 실험결과를 나타낸다.
-Network Expansion
그림 (b)와 같이 network structure를 modify하는 방법을 시도하여 실험을 진행하기도 했다. 해당 방법은 Network Expansion이라고 불리며, 기존의 layer에 node를 추가하는 방식을 수행한다. 각 weight별로 초기화 하는 방식이 다른데, 그림에서 나타는 것처럼 이전 Node 전체에서 새로운 Node로 이어지는 가중치 모두는 Net2Net와 같은 방식으로 초기화 한고, 새로운 node에서 original node로의 가중치는 0으로 초기화한다. 기존의 weight들은 freeze한다. Table (b)는 해당 실험을 나타낸다.
실험결과 network expansion은 feature extraction 보다 성능이 더 낫지만, 새로운 task는 LwF가 가장 성능이 좋았다.
-L2 Soft-Constrained Weights

fine-tuning loss에 해당 term을 추가하는데, 이는 original에 가까운 network parameter를 유지하기 위함이다. (new task에 대해서 parameter가 drift해 주는것을 막아주기 위함인듯) 해당 방법을 baseline으로 두고 논문에서의 LwF 방법이 해당 방법에 대한 성능을 outperform하는 지를 실험한 결과, 위의 Table(b)를 통해 LwF의 성능이 더 좋다는 것을 알 수 있다.
-Choice of Response Preserving Loss
LwF의 old task에 대한 loss로 label을 기존의 logit을 사용하여 학습할때, L1, L2, cross-entropy, KD의 T=2 사용, 4가지 방법에 대해서 비교를 위해 실험을 진행하였다. 해당 결과는 위의 Table의 (c)에 해당하고 L2의 성능만 underperform하였다.
-Effect of Lower Learning Rate of Shared Parameters
fine-tuning에서 shared parameter에 대한 learning rate를 줄이는 것이 old task에 대한 성능 저하를 방지할수 있는지에 대해서 실험을 진행하였고 이는 위의 Table(d)에 해당한다. 결과적으로 learning rate를 낮게하는 것은 old task에 대한 성능저하를 막지 못했고, 이는 단순히 shared layer의 학습률을 줄이는 것만으로는 old task의 성능을 보존하는데 있어서 충분하지 않다는 것을 보여준다.
논문 출처

